跟我一起学机器学习(第二版前言)#
一转眼距离《跟我一起学机器学习》出版上市已经3年有余,如今第二版的内容也总算定稿了。由于在第一版内容出版之初我们便发现它并不够完美,但秉持“不要等到变完美再行动,应该在行动中变完美”的想法,最终我们还是选择了出版,因此在出版之后我们便开始继续补充和完善相关章节的内容。
学习方法#
有了前车之鉴,此次我们更加注重全书内容的逻辑性、严谨性和完整性,期间也参考了不少优秀材料,如《统计学习方法》、《动手学深度学习》、《The Elements of Statistical Learning, Data Mining, Inference, and Prediction》、《Machine Learning》和 Scikit-Learn 实现源码等。
同时,我们也更加严格地按照了先前提出的“5层次3阶段”学习理念框架来对《跟我一起学机器学习》第一版的内容进行修订和补充。

学习一个算法就好比遍历一棵大树上的所有枝节,算法越复杂对应的枝叶也就越繁茂。一般来讲通常有两种方式遍历这棵大树:深度优先遍历和广度优先遍历。对于有的人来讲可能适合第一种,即从底部的根开始,每到一个枝干就深入遍历下去,然后回到主干继续遍历第二个枝干,直到结束;而对于有的人来讲可能更适合第二种,即从底部的根开始,先沿着主干爬到树顶以便对树的整体结构有一定的概念,然后从根部开始像第一种方式那样遍历整棵大树。相比于第一种方式,第二种方式在整个过程中更不易“迷路”,因为一开始便对这棵树的整体结构有了一定的了解。所以,我们一贯主张:先抓主干,后抓枝节。
进一步,对于一个算法的学习,我们还将它归结成了5个层次(3个阶段):
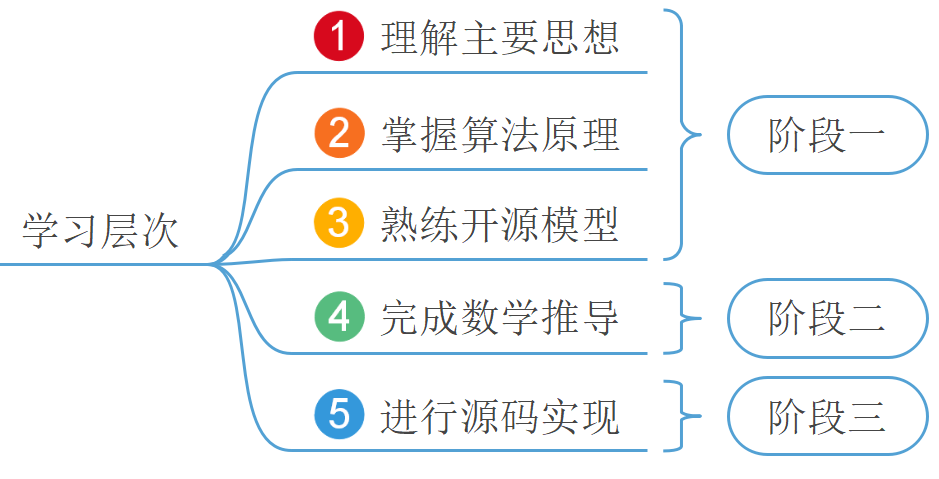
其中,阶段一可以看成先从大树主干爬到树顶一窥大树全貌的过程,因为对于一个算法来讲最基本的就是它所对应的思想,而这也是一个算法的灵魂所在。阶段二和阶段三可以看成遍历完整棵大树后的层次,它是对算法里细枝末节的具体探索。
这样的学习顺序可以打乱吗?我们的回答是:当然可以,只有适合自己的方法才是好方法。不过,对于绝大多数人来讲,我们认为应该遵循上面这一学习顺序。不过遗憾的是现在大多数读者的学习顺序是①②④⑤③或者是①②④③⑤。这两种学习顺序的弊端在于很多算法在其数学推导过程中难度较大,当克服不了这个困难时很多读者往往就会停滞不前,而这一问题在初学者当中尤为突出。最后导致的结果便是既没有学会怎么用,也不知道为什么。
相反,我们主张先学会怎么用,再探究为什么。在学习过程中最重要的是要形成一个良好的正向循环,这样才会有继续学习下去的动力。方法论本身也远大于学习材料的选择。
学到什么时候?#
对于一个算法到底应该学到什么层次同样也是初学者所面临的一个问题。可以想象,如果没有事先将一个算法的学习过程归结为这3个阶段,此时我们还真不知道该如何回答这一问题。因此我们的建议是,对于所有的算法来讲阶段一是必须完成的,对于一些相对容易的算法(如线性回归)可以要求自己达到上述3个阶段,而对于那些难度较大的算法(如支持向量机)可以根据自己的定位选择。同时需要注意的是,对于任何一个算法的学习极少人能做到学一遍就全懂的境界,所以也不要抱着学一遍就结束的想法。
因此,大家在实际学习过程中可以在第1次学习时先达到阶段一,然后在第2次学习时再达到阶段二,因为分阶段学习方式更能够使自己获得满足感,获得继续学下去的乐趣。最后,按照以上步骤进行,学习3~4个算法后,便算得上是初窥机器学习的门径了。
相较于第一版,第二版内容的主要变化在于:首先,对原有章节中的内容进行了补充和修订,以符合3阶段框架的对应内容;其次,对原第6章和第7章的顺序整体进行了交换,原第8章进行了拆分及内容顺序调整(拆分成了第8、9两个章节),原第9、10章中小节内容顺序进行了调整以符合本书叙述理念;最后,新增了第12降维算法和第13章自训练与标签传播算法,以扩充机器学习领域常见经典算法。最终形成了现在的《跟我一起学机器学习》第二版的内容,其中第1、2、3、7、10、12、13章由王成修订编写,第4、5、6、8、9、11章由由黄晓辉修订编写。同时,为了满足不同读者的学习需要,此次我们还为每个章节录制了对应的讲解视频。
本书特色#
从本书成文开始,我们就尽量选择了以直白的方式阐述每个算法背后的思想与原理。尽管这看起来可能有些口语化,但极大地降低了学习门槛,尤其是对于非计算机专业的读者来讲。同时,对于一些重要而又难以理解的概念,我们也会尝试2~3次以不同的口吻进行阐述。例如在第3章中用了下面这段话阐述为什么需要用到最大似然估计:
我们知道,在有监督的机器学习中都是通过给定训练集,即$({{x}^{(i)}},{{y}^{(i)}})$求得其中的未知参数$W$和$b$。换句话说,对于每个给定的样本${x}^{(i)}$,事先已经知道了其所属的类别${y}^{(i)}$,即${y}^{(i)}$的分布结果是知道的。那么,什么样的参数$W$和$b$能够使已知的${{y}^{(1)}},{{y}^{(2)}},\cdots ,{{y}^{(m)}}$这样一个结果(分布)最容易出现呢?也就是说,给定什么样的参数$W$和$b$,能使当输入${{x}^{(1)}},{{x}^{(2)}},\cdots ,{{x}^{(m)}}$这$m$个样本时,最能够产生已知类别标签${{y}^{(1)}},{{y}^{(2)}},\cdots ,{{y}^{(m)}}$这一结果呢?
尽管这段话读起来可能有些啰唆,但只要各位读者认真体会,一定会受益匪浅。
回顾过去5年时间,人工智能领域发生了翻天覆地的变化。大语言模型的横空出世改变了人们生活的方方面面,这当然也包括了我们的学习方式以及对待传统机器学习的态度。因此我时常听见有人问到,既然现在已经有大模型了我们还有必要去学习传统机器学习算法吗?对于类似问题,我的回答一贯都是要,当然要,但又不需完全要。为什么呢?
首先,作为一个人工智能领域的从业者,毋庸置疑你应该掌握常见经典算法所有阶段一内容的学习,剩下两个阶段按需再学,因为算法本身的应用可能是其次但其背后的思想却值得我们借鉴和思考;其次,传统机器学习依然是理解现在大模型底层思想与关键技术的基础支撑,在模型训练、数据预处理中都发挥着重要作用。例如聚类、逻辑回归、TF-IDF、N-gram等在大模型数据预处理中的应用,大模型网络结构中全连接层与逻辑回归的联系、层归一化与标准化的联系以及残差连接、丢弃法与集成学习的联系等等,这些都是机器学习的影子。
自1959年人工智能先驱亚瑟·塞缪尔创造了“机器学习”一词以来,机器学习已经走过了近70年的时间。机器学习从最初的简单规则推理,演化为支撑现代人工智能体系的核心技术。如今我们进入了“大模型时代”,但这并不意味着传统机器学习已被淘汰,相反,它像是深海中的基石支撑着庞大的模型建筑,使得AI系统得以稳健运行与持续进化。
在工作之中我时常感叹一些中间件的设计模式是如此之巧妙,但我知道很大程度上这都要归功于对传统数据结构的理解。所以,无论今后大模型会如何发展,我相信算法的本质不会变,思维的根基依然在“机器学习”之中。正因如此,学习机器学习不仅是为了掌握一门技术,更是为了获得一种我们身处大模型时代思考问题的方式。希望《跟我一起学机器学习》这本书能够让更多对人工智能领域感兴趣的人重新认识这门学科的魅力!
最后,由于我们才学和资历尚浅,书中也一定存在着这样或那样目前尚未发现的错误,还请各位读者海涵与见谅。同时,也欢迎各位同行前辈对本拙作的不吝指教。作为补救,后期我们也将提供持续跟进的勘误追踪,各位读者可以在本书配套的GitHub仓库中获取。在今后的岁月里,我们也将不遗余力地持续去打磨《跟我一起学机器学》和《跟我一起学深度学习》这两本书中的内容,力争以最直观、最简洁和最有新意的语言将各个算法的原理与实现呈现在各位读者面前,继续秉持“为往圣继绝学”的初心。
2025年11月 于上海
章节导航
机器学习环境配置教程,介绍 Conda 安装、Python 环境管理、Jupyter 与 PyCharm 配置,帮助你快速搭建开发环境。
线性回归教程,系统讲解单变量与多变量线性回归、多项式回归、梯度下降和回归评估指标。
逻辑回归教程,介绍二分类与多分类建模、损失函数推导、决策边界和分类评估指标。
机器学习泛化教程,讲解过拟合与欠拟合、偏差方差、L1/L2 正则化、交叉验证和特征标准化。
K近邻教程,介绍 KNN 原理、距离度量、kd树构建与搜索,以及 sklearn 实现与实战示例。
文本特征入门,讲解词袋模型、TF-IDF、词云图和基于 KNN 的垃圾邮件分类实践。
朴素贝叶斯教程,介绍贝叶斯估计、朴素贝叶斯原理,以及高斯与多项式朴素贝叶斯实现。
决策树教程,系统讲解决策树原理、ID3、C4.5、CART 与剪枝方法,并配合代码实现。
集成学习教程,介绍 Bagging、随机森林、AdaBoost 与 Gradient Boosting 的核心思想和实现。
SVM 教程,讲解支持向量机原理、软硬间隔、核函数、KKT 条件与 SMO 求解方法。
聚类算法教程,介绍 KMeans、层次聚类、密度聚类、聚类评价指标和 K 值选择方法。
降维算法教程,讲解主成分分析 PCA、降维步骤,以及核主成分分析的基本思想。
半监督学习教程,介绍 Self-Training、Label Propagation 与 Label Spreading 的原理和实现思路。
本页直达文章
目录思维导图
本节围绕学习思维导图展开,系统介绍其核心概念与相关内容。